Mã số N2162: Máy biến áp trong đếm đám đông – giải pháp ước lượng mật độ đám đông
Các mạng 4.0 với các công nghệ cốt lõi như blockchain (chuỗi khối), trí thông minh nhân tạo (Artificial Intelligence), Internet vạn vật (Internet of Things), công nghệ in 3D, thực tại ảo, … đang tác động trực diện tới hầu hết các lĩnh vực của đời sống kinh tế-xã hội. Cùng với đó là nhu cầu xây dựng thành phố thông minh (Smart City) với hệ thống giám sát bằng các camera giám sát CCTV - thông qua các thiết bị và phần mềm với cốt lõi chính là trí tuệ nhân tạo để giúp tự động giám sát, quản lý sự vật cũng như con người. Trong đó, công đoạn xử lý các camera giám sát là công đoạn rất quan trọng vì nó liên quan đến việc quản lý các hoạt động của người. Đã có nhiều nghiên cứu cho việc giám sát đám đông tuy nhiên các giải pháp đưa ra vẫn còn nhiều hạn chế cần khắc phục: bị che khuất, ánh sáng phân bố không đồng đều, độ giãn…
Để giải quyết vấn đề trên chúng tôi đã thực hiện đề tài nghiên cứu: “Máy biến áp trong đếm đám đông” với mong muốn đưa ra được giải pháp ước lượng mật độ đám đông với độ chính xác cao hỗ trợ cho việc cảnh báo sớm ở những nơi công cộng, ngoài ra giải pháp cũng có thể áp dụng cho các cửa hàng, rạp chiếu phim,… quản lý được lượng khách vào ra cửa hàng để đưa ra quyết định cho công việc kinh doanh của mình.
Mô tả chung về hệ thống

Việc ước lượng đám đông cần giải quyết một số vấn đề sau:
- Đánh dấu bằng cách chấm tại mỗi điểm đầu người trong ảnh.
- Xây dựng bản đồ mật độ xác thực.
- Xây dụng bộ phân lớp “mềm” cho ảnh tương ứng với các mật độ đông, vừa, thưa.
- Xây dựng mô hình mạng để tạo bản đồ mật độ ước tính.
Ở đây, việc đánh dấu có thể được thực hiện bằng tay hoặc tự động. Các bộ dữ liệu sẽ được dùng để kiểm nghiệm là UCF_CC_50, ShanghaiTech đều đã được đánh dấu tại mỗi điểm đầu người. Để tăng số lượng mẫu cũng như để áp dụng việc tiền phân loại mẫu có người hay không có người, các mẫu sẽ được chia thành 9 phần bằng nhau (lưới 3x3). Việc phân chia này hoàn toàn có thể thay đổi thành các lưới có kích thước khác. Để thuận lợi cho việc mô tả, các phần này sẽ được gọi là patch ảnh. Patch ảnh sẽ được chuyển thành ảnh độ xám khi đưa vào mô hình.
Các phương pháp ước lượng mật độ và đếm số người hiện nay thường chỉ chú trọng vào việc xây dựng mô hình của mình. Tuy nhiên, khi gặp các cảnh không có người như cảnh tòa nhà, cây cối, mây... thì các phương pháp này luôn ước tính ra một con số khác không. Vì vậy, nhóm tác giả đề xuất xây dựng thêm một bộ phân lớp có người hay không có người. Ý tưởng là dùng một mạng học sâu để tiền phân loại ảnh. Trong giải pháp này, nhóm tác giả sử dụng mạng VGG-16 vì nó có thể dễ dàng triển khai thực hiện (implement) và thời gian huấn luyện nhanh. Với những ảnh được phân loại là không có người, số đếm ước lượng được sẽ được gán bằng 0.
Các bộ dữ liệu chuẩn để thực nghiệm
Bộ dữ liệu UCF_CC_50 : Bộ dữ liệu bao gồm 50 ảnh ở môi trường có mật độ người cực kỳ đông đúc. Các ảnh được thu thập từ dịch vụ lưu trữ ảnh FLICKR với các kích thước khác nhau. Mỗi ảnh có số người từ 94 đến 4543 và trung bình số người trong một ảnh là 1280 người. Bộ dữ liệu chứa 63075 đầu người đã được đánh dấu.
Bộ dữ liệu ShanghaiTech: Bộ dữ liệu có tổng cộng 1198 ảnh với 330165 đầu người đã được đánh dấu. Bộ dữ liệu được chia thành 2 phần: Tập A bao gồm 482 ảnh được chọn ngẫu nhiên trên Internet và Tập B bao gồm các ảnh kích thước 768x1024 được chụp ở khu vực đô thị ở Thượng Hải. Mật độ người ở Tập A đông hơn mật độ người ở Tập B.
Phương pháp đánh giá
Các độ đo Mean Absolute Error (MAE), Mean Squared Error (MSE) và Mean Relative Error (MRE) được dùng để đánh giá hiệu năng của các phương pháp, được định nghĩa như sau:
Như vậy, chỉ số MAE, MSE và MRE càng thấp thì mô hình càng tốt.
Khi nhấn “Select an image” để chọn ảnh đám đông. Chương trình sẽ ước tính bản đồ mật độ và trả về số người đếm được “Estimated count”. Do phần giao diện của chương trình được viết bằng thư viện Tkinter nên bản đồ mật độ thể hiện ra là màu trắng đen.

Tạo dữ liệu để huấn luyện và kiểm thử mô hình:
Dữ liệu để huấn luyện bao gồm: Các ảnh được chia nhỏ ra thành các patch ảnh (dùng lưới 3x3) từ 2 tập dữ liệu ShanghaiTech và UCF_CC_50. Bản đồ mật độ xác thực của patch ảnh. Để tạo dữ liệu huấn luyện: Chạy file “create_datasets.m”.
Huấn luyện mô hình trên giao diện console
Các bước để thực hiện huấn luyện mô hình trên giao diện console:
- Bước 1: Chạy file “train_classifier.py” để huấn luyện Human Classifier.
- Bước 2: Chạy file “differential_train.py” để huấn luyện các Regressor.
- Bước 3: Chạy file “coupled_train.py” để huấn luyện Switch Classifier.
Sau khi huấn luyện xong, bộ trọng số của mô hình sẽ được lưu dưới dạng *.pkl nằm trong thư mục “models”.
1.1.1. Kiểm thử mô hình trên giao diện console
Các bước để thực hiện kiểm thử mô hình trên giao diện console:
- Bước 1: Chạy file “test_classifier.py” để kiểm thử Human Classifier.
- Bước 2: Chạy file “test_scnn.py” để kiểm thử mô hình không sử dụng Human Classifier.
- Bước 3: Chạy file “test_model.py” để kiểm thử mô hình đề xuất có sử dụng Human Classifier.
Kết quả kiểm thử của mô hình trên tập dữ liệu ShanghaiTech Part A như hình Vùng khoanh đỏ là kết quả khi dùng các độ đo MAE, MSE, MRE.
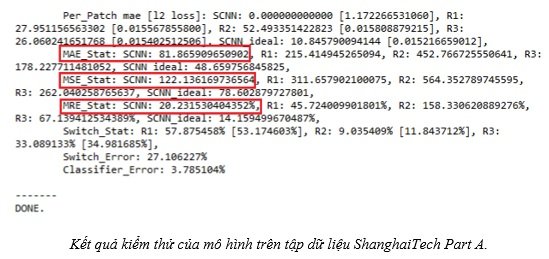
Kết quả thực nghiệm
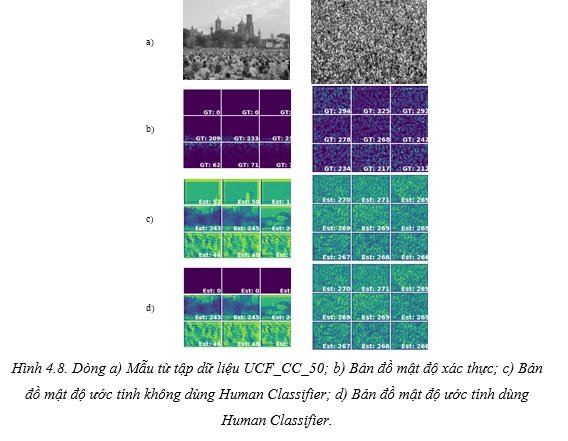
Tập dữ liệu UCF_CC_50
Tập dữ liệu này không chỉ thách thức về số lượng mẫu mà số người trong mỗi ảnh cũng biến động rất lớn. Nhóm tác giả sử dụng thích ứng để tạo bản đồ mật độ xác thực và sử dụng kiểm chứng chéo (cross-validation) 5-fold theo thiết lập của tác giả Idrees để đánh giá hiệu năng của mô hình
Từ hình 4.8 ta có thể thấy, vùng đám mây không có người vẫn được tính ra giá trị khác 0. Vì thế khi áp dụng thêm Human Classifer, vùng đó sẽ được ước tính thành 0, làm giảm độ lỗi khi đếm rất nhiều.
Từ số liệu thực nghiệm ở bảng 4.1 cho thấy, khi không sử dụng Human Classifier, việc kết hợp các bản đồ mật độ dựa trên trọng số cho kết quả vẫn tốt hơn so với các phương pháp hiện tại. Với ảnh có mật độ người dày đặc thì việc áp dụng Human Classifier vào càng làm tăng tính hiệu quả của mô hình.

Đối với tập dữ liệu ShanghaiTech Part A, nhóm tác giả chọn thích ứng để tạo bản đồ mật độ xác thực, còn tập dữ liệu ShanghaiTech Part B, do mật độ người ở tập dữ liệu này phân bố khá rời rạc, nhóm tác giả chọn cố định để tạo bản đồ mật độ xác thực.

Để xem xét mô hình ước tính số người chính xác bao nhiêu phần trăm, nhóm tác giả sử dụng độ đo MRE, phương pháp đề xuất giảm 3% so với phương pháp Switch-CNN. Như vậy, mô hình đề xuất ước tính chính xác khoảng 80%, con số này là có thể chấp nhận được là vì bộ dữ liệu sử dụng có mật độ người đông, sai số khoảng 20% là hoàn toàn có thể chấp nhận. Còn với độ đo MAE và MSE, phương pháp đề xuất đều tốt hơn so với các phương pháp hiện tại trên cả 2 tập dữ liệu Shanghai Tech Part A và Shanghai Tech Part B.
Việc sử dụng bộ phân lớp để xác định vùng ảnh có người hay không, góp phần quan trọng trong việc tăng hiệu năng của mô hình. Nhóm nghiên cứu cũng đã khắc phục được nhược điểm của hai phương pháp MCNN và Switch-CNN để cải thiện hiệu năng của chúng. Thực nghiệm cho thấy, phương pháp cải tiến đề xuất đã đạt hiệu năng cao hơn so với các phương pháp hiện có ỏ hai bộ dữ liệu ShanghaiTech và UCF_CC_50. Phương pháp đề xuất này có thể đáp ứng đủ điều kiện để áp dụng vào thực tế.
Thông tin
Tên tác giả: Đỗ Phúc Thịnh
Đơn vị đồng hành
Đơn vị bảo trợ truyền thông
